Vision-Language Navigation on a Booster K1 Humanoid
An 8B vision-language-action model, a three-machine inference relay, and a humanoid that walks toward natural-language goals.
Role — Research lead — model deployment, relay design, robot integration, debugging
- Vision-language navigation results are usually reported in simulation. Getting the same behavior out of a real humanoid means solving distribution shift, latency, and control-loop problems the benchmark never mentions.
- Real-robot deployment · distributed inference/control loop
- Language-directed navigation is a building block for useful humanoids. The gap between a benchmark score and a robot that actually walks where you ask is exactly the gap this research explores.
- Research assistant under Dr. Yiyan Li, Fort Lewis College — leading the sim-to-real research effort.
Overview
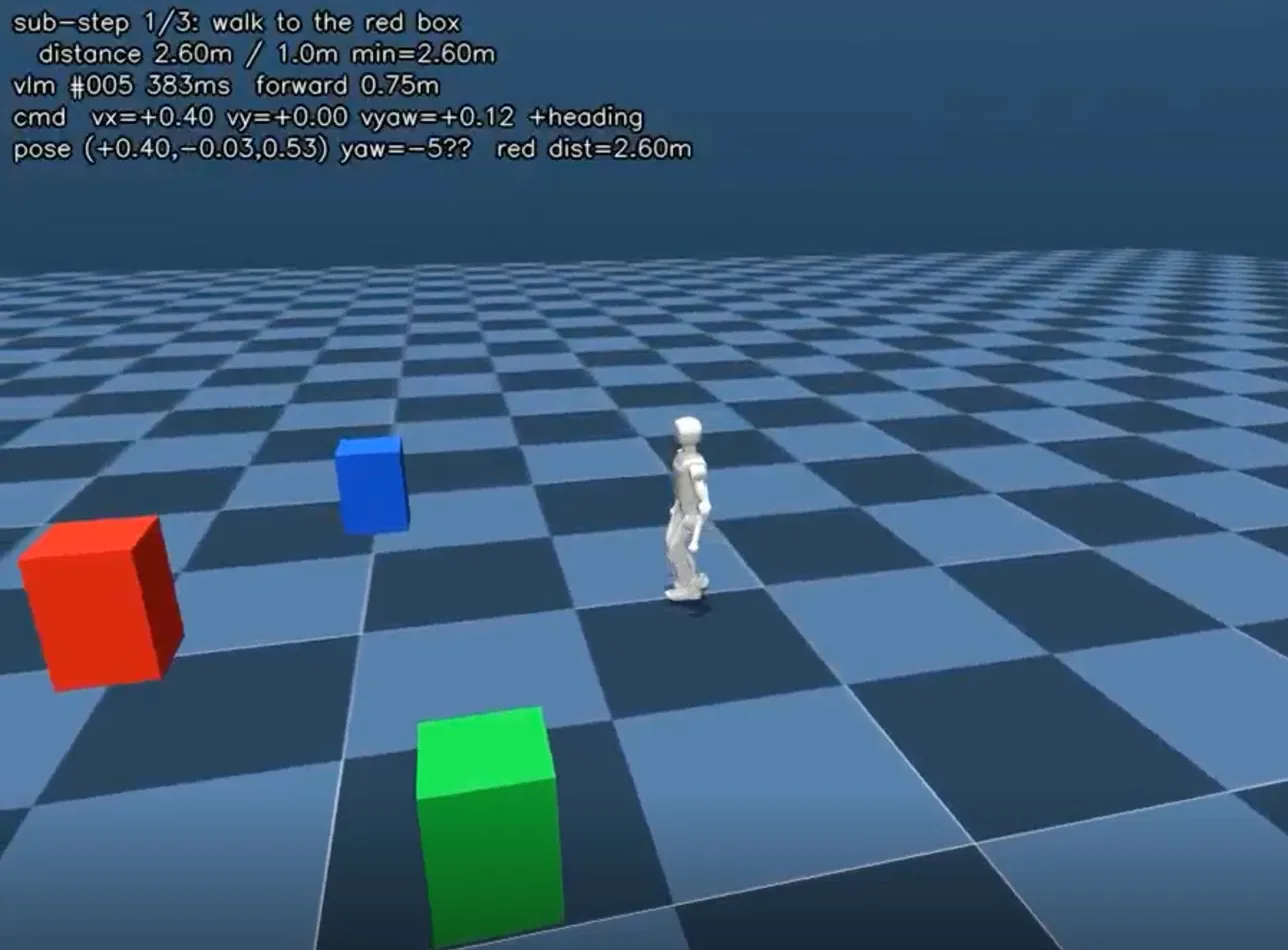
Sim-to-real research on the Booster K1 humanoid, led under Dr. Yiyan Li at Fort Lewis College. Give the robot an instruction like "walk to the volleyball and turn 90 degrees" and a NaVILA-style vision-language model interprets the camera feed, reasons about the scene, and emits actions in plain language — "move forward 75 cm" — which are translated into real-time velocity commands for a reinforcement-learned locomotion policy. NaVILA (UCSD + NVIDIA, RSS 2025) had no open implementation for the Booster K1; this deployment was built from the paper up. The architecture is two-tiered: vision-language planning at roughly 1 Hz over a 50 Hz RL locomotion policy.
Three machines share one control loop. The K1 streams camera frames to a relay/control node; frames are forwarded to the inference workstation where the 8B VLA produces navigation actions at roughly 1 Hz; actions are translated into velocity commands consumed by the 50 Hz locomotion policy. Telemetry flows back for monitoring and evaluation.
- Booster K1 — camera stream + SDK
- Relay / control machine
- Inference workstation — RTX 5090 · 8B VLA
- Velocity commands → robot
- Telemetry & evaluation

Contributions
- Reproduced the NaVILA pipeline for the Booster K1 with no open reference implementation — built from the paper up.
- Set up 8B VLA model inference on an RTX 5090 workstation and connected it to the robot over a relay/control machine.
- Built the loop: robot camera stream → inference → action decoding → SDK velocity commands back to the K1, pairing ~1 Hz planning with 50 Hz locomotion.
- Debugged real-deployment issues end to end — timing, framing, drift, and recovery problems that never appear in simulation.
Evidence & evaluation
Evidence
Demo video
attachedEmbedded above — the K1 walking to a volleyball on a natural-language instruction.
Architecture diagram
attachedTopology diagram in the gallery — machines, links, and loop rates.
Inference latency
attached~350 ms per inference step, shown live in the system overlay.
Failure-mode log
pendingDocumented on-hardware failures and recovery behavior (with clips or logs).
Instruction success protocol
pendingDefine the eval protocol (instructions, environments, n) before reporting rates.
Metrics
~350 ms / step
~1 Hz
50 Hz
Not yet measured
Define the eval protocol first; report n.
Limitations
- Vision-based humanoid navigation remains brittle; much of the current work is mapping exactly where the system breaks down and why.
- Evaluation on real hardware is still informal — success criteria need to be pinned down before quantitative claims are made.
Lessons & tradeoffs
- The model is rarely the bottleneck; the seams between machines are. Most debugging time went to the loop, not the network weights.
- Instruction-following demos hide a long tail — the gap between one good run and a reliable system is the actual research problem.
- Simulation results set expectations that hardware immediately renegotiates; treating deployment as its own engineering discipline was the unlock.
Artifacts
- Deployment demo
- System topology
- Deployment reportnot yet published
- Run logsnot yet published