Reinforcement-Learned Locomotion & Evaluation in Isaac Sim
PPO locomotion policies and benchmark-style evaluation in Isaac Sim / Isaac Lab, with sim-to-real transfer as the point, not an afterthought.
Role — RL training infrastructure, benchmark/evaluation setup, sim-to-real analysis
- Legged locomotion policies are easy to overfit to a simulator. The question is always the same: what in the reward, randomization, and evaluation setup actually predicts real-world behavior?
- Simulation training + evaluation pipeline
- Sim-to-real is the tax every embodied-AI system pays. Understanding it at the training-and-evaluation layer is what makes the humanoid deployment predictable instead of lucky.
- Part of the Booster K1 research program under Dr. Yiyan Li; training infrastructure built as the deployment substrate.
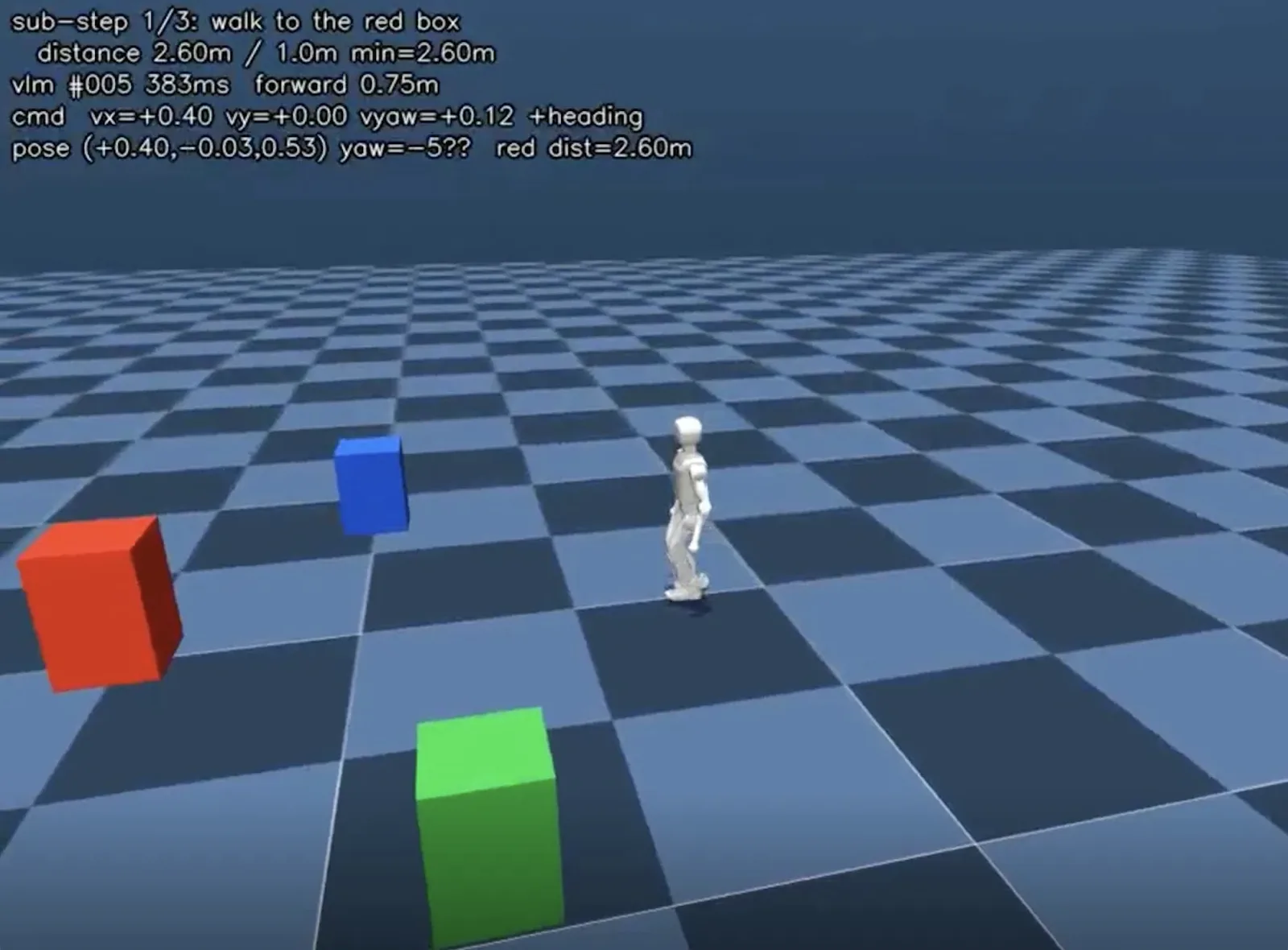
Overview
The training side of the Booster K1 research program: building reinforcement-learning infrastructure in NVIDIA Isaac Lab / Isaac Sim for the K1's velocity-tracking locomotion policy — the 50 Hz tier that executes what the vision-language planner decides. The work covers PPO training, benchmark and evaluation tooling, and the practical study of which simulated behaviors survive contact with hardware.
Standard modern RL loop: parallelized simulation environments feed a PPO learner; checkpoints flow into an evaluation harness that scores policies on defined tasks; results inform reward and randomization iteration — and the surviving policies deploy under the VLA planner on the real robot.
- Isaac Sim / Isaac Lab environments
- PPO training loop
- Policy checkpoints — 50 Hz control
- Benchmark & evaluation harness
- Deploy to K1 under VLA planner

Contributions
- Building PPO training infrastructure in Isaac Lab / Isaac Sim for the K1's velocity-tracking locomotion policy (50 Hz control).
- Running benchmark/evaluation passes over trained policies.
- [Specify as the work matures: environments, reward shaping decisions, randomization strategy, and which evaluations were designed vs. reused.]to fill
Evidence & evaluation
Evidence
Pipeline diagram
attachedTraining → checkpoint → evaluation loop in the gallery.
Training curves
pendingAttach reward/episode-length curves with config details.
Evaluation protocol
pendingDocument tasks, seeds, episode counts, and success criteria.
Sim-to-real comparison
pendingSide-by-side of simulated vs. real behavior for the same policy class.
Metrics
50 Hz
Not yet measured
Report only with the exact eval config attached.
Not yet measured
Env count, steps, wall-clock — measured, not recalled.
Limitations
- [State clearly which parts of the pipeline were built vs. configured — Isaac Lab ships strong defaults, and readers know it.]to fill
Lessons & tradeoffs
- Evaluation design is where RL work becomes science; without a fixed protocol, every policy looks fine in its own demo.
- [Add a concrete reward-design or randomization lesson from your runs.]to fill
Artifacts
- Evaluation writeupnot yet published
- Training / eval codenot yet published
- Pipeline diagram